








今年春节档,一部《流浪地球2》点燃了沉寂许久的中国科幻电影市场,也让MOSS这一电影里冷酷无情的强人工智能形象变得深入人心。
无独有偶,几乎是相同时期,ChatGPT凭借极其出色的文本生成和对话交互能力在世界范围内迅速走红,短短两个月月活用户已经破亿,刷新了消费级应用程序用户增长的速度纪录。
从某种角度看,ChatGPT之所以能够引发现象级的社会现象,除了海量数据训练引发的质变因素外,更重要的是在一个恰当的时机,满足了人们长期以对人工智能的想象,过往科幻作品中的猜想开始逐渐变为现实。
代变革的大幕已掀开一角,一场由OpenAI引领的全球AI大语言模型军备竞赛就此打响。
雨后春笋
3月14日,GPT-4正式发布,大语言模型开始具备图片和文字同时处理的多模态能力,继续占据先入为主的优势。
全球大厂中,率先回应的是百度。3月16日,百度大语言模型“文心一言”正式推出,对外启动邀测。据公开报道,文心一言具备五项核心能力:文学创作、商业文案创作、数理逻辑推算、中文理解和多模态生成。
紧接着,其他科技企业也陆续跟进。4月11日,2023阿里云峰会现场演示了通义千问的多项功能,并定向邀请企业用户进行体验测试;5月10日,谷歌时隔一年推出了新一代语言大模型PaLM2,被视为对此前发布会翻车的有力回应。
此外,还有复旦大学在2月21日发布的“MOSS”、清华大学3月28日发布的“ChatGLM-6B”、360于4月10日发布的“360智脑”、商汤科技4月10日发布的“商量”、5月6日发布的“讯飞星火认知大模型”等等。
截至5月,据不完全统计,国内已有超过40家公司、机构发布了大模型产品或公布了大模型计划。项目数量井喷式的爆发,可预见的是,下半年的国内AI大模型市场竞争将会变得空前激烈。
不止于“大”
提到大模型,很多人的关注点都会放在“大”字上,毕竟足够量级的参数是语言模型实现智能涌现、形成质变的基础。比如,不少大语言模型的参数量级达千亿级,这也就意味着较为丰富的语言知识与较广泛的语境理解能力。
不过,目前类GPT模型普遍采用的是Transformer架构,所以必然包含市面上存在的大量文本数据例如小说、教科书、论坛、开源代码等内容的无监督预训练过程,在此基础上,仅需根据具体任务输入少量的标签数据进行监督学习。在这样的模式下,训练数据集质量的重要性开始愈发凸显。
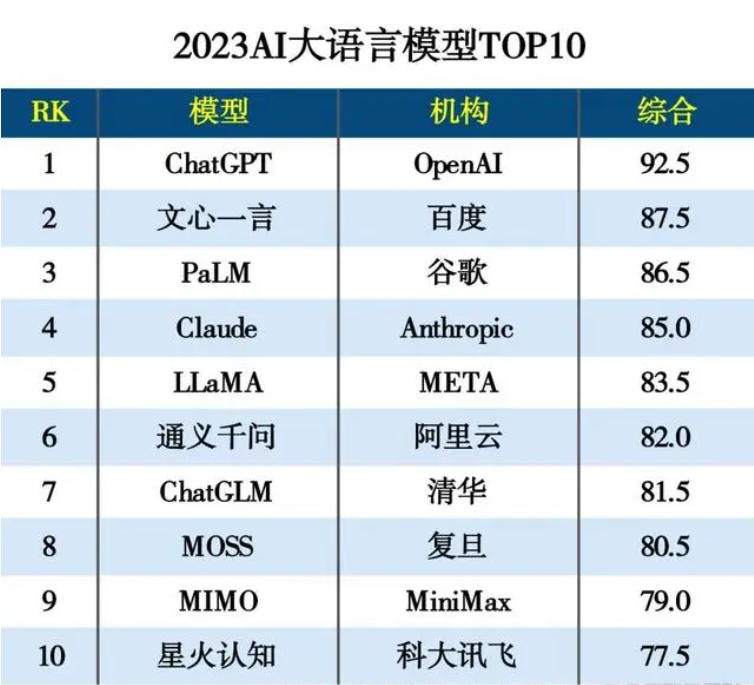
本次评测的结果就可以印证这一点。评测主要考察各大语言模型在中文语境下的理解与生成能力,基于目前用户对大语言模型在生活、办公的普遍需求,选取语义理解、逻辑推理、情感分析、百科知识、文本质量五个通用底层维度,以评估各大语言模型协助用户日常处理事务、解决核心问题的能力,取0(无效应答)、1(有效应答)两个分数,其中文本质量维度按照行文逻辑、信息密度,取0(一般)、0.5(良好)、1(优秀)三个分数。
评测问题也有别于针对BERT类判别式AI模型的选择问法,采用更加适合AI生成式模型的相对开放式问法,以下为部分问题及回答评分示例:
在“I've got a thing for you,用文言文表达这句话”这一问题中,ChatGPT给出的回答是:“朕对汝有所钟情。”理解正确,但生成文本质量欠佳,取0.5分。文心一言的输出内容:“吾心向汝,实生情之。”文义相符,质量较高,取1分。星火认知大模型回答为:“吾有物以赠君。”存在理解有误的情况,取0分。
从结果看ChatGPT在语义理解、逻辑推理、百科知识、文本质量四项中分别以18、19、19、18.5排名第一,综合表现位居榜首,特别是在科技、学术、新闻等领域的文本生成部分领域表现突出,不过在相对复杂的情景下的情感识别,以及散文、诗歌、文言文等较为考察深度理解能力方面表现相对乏善可陈;
文心一言,作为首个全球大厂推出的知识增强大语言模型,本次排名位居国产大语言模型之首,效果仅次于ChatGPT,且在语义理解、情感分析两项位列第一,分数分别为18、19,这或许与百度使用的自有数据集有关,在质量较高的文库文本、百科数据等中文语料的训练下,在语义理解和情感分析方面具有很高的精度,可以识别出复杂的情感表达和语言隐喻;
除此以外,谷歌PaLM在逻辑推理部分(分数19)、通义千问在语义理解(分数17)、清华ChatGLM在文本质量(分数15.5)等成绩均可圈可点。
结语
未来大模型的迭代也将更有针对性,对开发者的评估能力提出更高的要求。如何在有限的时间和资源条件下做出客观的评价并给出有用的反馈,让数据团队更有针对性地准备数据,让研发不偏离方向,保障模型的健康迭代,将是所有行业从业者的共同挑战。
您可能关注: 大模型
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。

