








Sora,已经成为人工智能界的开年“王炸”。
2月16日,OpenAI发布Sora大模型,仅需通过文本即可自动生成视频,这也是继文本模型ChatGPT和图片模型Dall-E之后,又一极具颠覆性的大模型产品。
文本生成视频并非始于Sora。据不完全统计,截至去年年底,全球范围已涌现了包括Runway、Pika、Stable Video Diffusion在内的超过20款同类产品。但Sora的登场无疑带来了一场革命性冲击,其展现出来的卓越性能近乎达到对同类产品的“碾压”级别。
OpenAI祭出Sora后,中美的AI差距会如何演变,这一步是“天堑”,还是“咫尺”?
Sora颠覆性“世界模型”,AI差距会加大?
Sora所展示的颠覆性体现在多个维度,可以直接输出的视频长达60秒,并且视频内含复杂精细的背景环境、动态多变的运镜、多样化的角色表现以及一镜到底或切换多机位的无缝对接,从人物微妙的表情变化至动物生动的姿态模拟,都足以以假乱真。
在OpenAI发布的视频中,一名时尚女性走过喧闹繁华的东京街头,背景建筑、街道以及人像的逼真程度,都保持了高度一致性,哪怕是各种镜头的蒙太奇,都没有出现明显的失真。

有人评价,由Sora生成的视频,无论是光影色彩的转变,还是镜头移动,甚至细微到纹理结构变化,都呈现出较高质感。它还能模拟现实世界的物理规律,像“一杯咖啡中,两艘海盗船展开了激烈的战斗”这段视频,不仅呈现了咖啡的流体动力学和逼真的光影渲染,还运用了光线追踪和移轴摄影技术等,技能强大。
OpenAI强调,“Sora是能够理解和模拟现实世界模型的基础,我们相信这一功能将成为实现通用人工智能(AGI)的重要里程碑。”
Sora的横空出世引发了关于中美AI差距是否进一步加大的热议。360公司周鸿祎指出,尽管国内大模型发展水平接近GPT-3.5,但与GPT-4.0相比仍存在一年半左右的差距。
周鸿祎认为,OpenAI可能还握有未公开的秘密武器,“中国跟美国的AI差距可能还在加大。”
与此同时,不少业内人士表示,中美AI发展的根本差距或许不在于技术本身。
OpenAI,数据是“秘密武器”,游戏引擎或是关键
《IT时报》记者注意到,根据OpenAI发布的技术报告,Sora强大能力归功于两点:其一是使用了基于Transformer的扩散模型(Diffusion Model);其二是将不同类型视觉数据转化为统一格式——像素块(patch),从而能利用数量庞大、质量过硬且算力性价比高的数据。
技术报告中,OpenAI并没有披露训练来源和具体细节,业内人士认为,数据很可能是Sora成功的最关键因素之一。
“我觉得最核心的一点是OpenAI有足够的数据。”Logenic AI联合创始人李博杰向《IT时报》记者表示,OpenAI之所以能够在生成模型领域取得突破,主要原因在于,其数据质量和数量上的显著优势。
浙江大学百人计划研究员、博士生导师赵俊博在接受澎湃新闻采访时也表示,对于Sora采用了怎样的数据进行训练,圈内依然众说纷纭,推测可能是运用了游戏引擎生成的大规模数据:“可能是游戏引擎里面吐出来这种数据,但它这个数据到底怎么收集、如何生产加工,最后如何喂到Sora里面进行管线化的预训练,我们确实不知道。”
OpenAI曾发布两个20秒长的Sora版《我的世界》演示视频,研究人员向Sora提供包含“Minecraft”(《我的世界》游戏)一词的提示后,Sora可以渲染出与《我的世界》游戏极其相似的HUD、高保真度渲染世界及游戏动态,同时还能控制玩家角色。
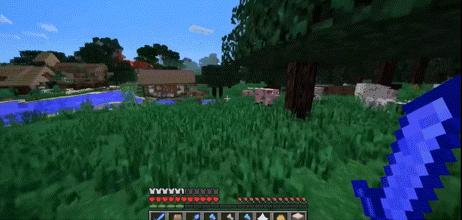
值得一提的是,去年8月,OpenAI官宣了有史以来第一次收购,收购对象为制作开源版《我的世界》的初创公司Global illumination。李博杰猜测,从Sora版《我的世界》演示成果来看,OpenAI对Global illumination收购或许为Sora的数据积累做了一定贡献。
在算力方面,虽然OpenAI训练Sora模型使用的GPU卡数量并非无法企及,但其他公司在具备足够硬件资源的情况下,仍然难以复制OpenAI的成功,主要瓶颈还是在于如何获取和处理大规模高质量的视频数据。
《IT时报》记者注意到,收购Global illumination的同时,OpenAI宣布以创新方法来训练AI模型,有望省去标注大量资料的训练过程。
彼时OpenAI所公布的VPT“视频预训练模型”,让AI学会了在《我的世界》里从头开始造石镐。原本整套流程需要一个骨灰级玩家至少20分钟的时间才能完成,总计要操作24000次。而研究人员首先收集一波数据标注外包们玩游戏的数据,其中包含视频和键鼠操作的记录。然后,利用这些数据制作逆动力学模型(inverse dynamics model,IDM),从而推测出视频里每一步在进行的时候,键鼠都是怎么动的。
这样,整个任务就变得简单多了,只需比原来少很多的数据就可以实现目的。这项研究发表于2022年6月,同时文中还注明这个工作已经进行了一年之久,也就是说,OpenAI至少从2021年起就开始进行这项研究。
“即使是谷歌这样全球数据量最大的公司,在训练大模型时,训练数据也未必能比OpenAI更好。”相比之下,国内公司在数据上的积累和利用上可能还有一定差距。李博杰认为,OpenAI的先发优势决定了早期的数据壁垒,对于后进入市场的公司来说,增加了追赶的难度。
一方面,由于政策变化和其他限制,后来者可能无法获取之前可用的一些关键数据;另一方面,随着AI生成内容越来越多地充斥互联网,原始的真实世界数据被“污染”,使得获取高质量、无偏见的训练数据更加困难。
这与GPT-4的情况类似,尽管其成功离不开强大的算力支持,但最核心的竞争优势仍然是庞大、高质量的数据集。许多其他公司即便有充足的计算资源,但在构建和利用同等规模与质量的数据集上遇到了挑战,因此未能及时跟进推出类似的尖端模型。
国内AI,文本大模型进步明显,多模态大模型差距较大
OpenAI在技术报告中承认,Sora可能难以准确模拟复杂场景的物理原理;可能无法理解因果关系;还可能混淆提示的空间细节;可能难以精确描述随着时间推移发生的事件,例如遵循特定的相机轨迹等。
“Sora本质上还是一个规模相对比较小的模型。”对此李博杰认为,Sora出现更大的意义是证明了构建世界模型的重要性,并为行业指明了一条正确的研究路径,但未来的发展趋势依然是像GPT-5这样端到端多模态大模型,能够更好地理解和生成包含复杂情节和逻辑的内容。
李博杰告诉《IT时报》记者,目前国内外在AI大模型发展上的差距主要体现在多模态模型的发展上。在国内,部分公司已经能在文本模型上取得显著成果,达到或超过GPT-3.5的水平,并正朝着GPT-4的方向努力追赶,这显示出国内企业在单一文本处理领域的实力和进步速度。
然而,在多模态模型研发方面,国内许多专注于大模型开发的公司可能尚未充分认识到多模态技术的重要性,没有投入足够的人力、物力及财力进行相关研发。李博杰认为,市场上普遍认为GPT-4等文本模型表现优秀,因此更多地将重心放在文本处理上,而忽视了多模态模型的构建与发展。
另外,国内公司在探索创新路径时可能会受到资源限制,包括算力、人才密度等方面的制约,相较拥有庞大计算资源和顶尖人才集中的OpenAI等欧美公司,中国公司在自主创新方面面临更大的挑战。因此国内企业倾向于跟随国际领先者已验证的技术路线,这种策略相对更为稳健且高效,可以快速缩短技术差距。
对齐,国外大模型成本太高,国内应用场景是机会
不少业内人士认为,在底层基础技术原理上,Sora 并未有实质性的突破,广发证券分析,Sora或应更多理解为类似于ChatGPT,基于同样的技术原理,在暴力美学下的又一次重要“量变”。
中科深智创始人兼CEO成维忠在接受媒体采访时表示,Sora算法意义上突破不大。Sora一方面通过极致的暴力美学,用巨量算力解决帧与帧之间的时序一致性问题,即在Sora中,不但用扩散模型解决同一帧的生成,也用扩散模型解决帧之间的时序生成,这也决定了Sora的视频生成成本短时间内无法降低。在无法解决“幻觉”的情况下,要想生成真正可控可用的视频,短期内成本高昂。
这些局限或许也将成为后来者的机会。
“就像现在大家公认GPT-4是最厉害的,但你要真的做公司,会发现根本坚持不了几天,因为GPT-4太贵了。所以我们真正在公司里面使用的这些模型大部分都不是GPT-4,或者用的是开源大模型,能用7B的就不用70B的,能用70B的就不用 GPT-4,价格能差100倍以上,成本是一个非常关键的因素。”李博杰透露。
正如其所说,GPT-4虽然强大,但成本确实是一个现实问题,这也促使企业在实际应用中选择性价比更高的解决方案,如开源模型或规模更小的商用模型。而针对Sora视频生成,李博杰估算其一条视频的成本在几美元到几十美元不等,如果普及到大众使用,成本需要降到目前的1%才能接受,降低成本的同时提高生成质量和逻辑连贯性,是亟待解决的关键挑战。
事实上,随着AI技术的发展,内容生产的各个环节都已经开始经受影响并发生深刻变化。
产品经理Mixlab无界社区和ComfyUI中文爱好者社区发起人PM熊叔告诉《IT时报》记者,对于本地市场的需求,诸如百度文心一言等国内研发的大规模预训练模型,在满足普遍性应用场景时展现出相当不错的实用性,但在处理复杂需求时,还是与国外顶尖大模型存在一定差距。不过,对于大部分现有的生产工具需求而言,当前开源和国内商业化模型已经能够提供基本可用且较为满意的服务,尤其是随着应用场景的逐渐丰富,国内大模型落地在加速。
PM熊叔注意到,去年上半年,AI在内容生产中还只是承担一些简单的配音工作,用于批量生产质量较低的影视解说等场景。但到了下半年,AI技术进一步渗透到内容制作的重要环节,如重绘动画作品,正规团队开始利用AI技术来提升作品质量和降低生产成本。另一方面,AI化的分析和辅助工具也在影视行业中逐渐普及,改变了原有的创作流程,使得专业影视作品能够通过AI生成的方式降低成本并提高可控性。
在这过程中,开源社区的力量不容小觑。PM熊叔指出,OpenAI的部分模型虽然并未完全开源,但其研究成果和论文发表对全球科研团队和开源社区具有重大启发作用。一旦有类似功能的论文或部分技术细节被公开,众多开源团队和开发者会迅速跟进,复现、改进并推出开源版本的模型。例如,GPT系列的成功激发了众多开源项目去构建类似的语言模型,这些模型在不断优化和迭代之后,其性能表现能够逐渐逼近,甚至在某些特定任务上与闭源先进模型相媲美。
李博杰也认为,在泛娱乐类应用领域,国内公司借助丰富生态与应用场景的优势,或能在应用层面上实现赶超,并有机会通过出海拓展市场。
[免责声明]如需转载请注明原创来源;本站部分文章和图片来源网络编辑,如存在版权问题请发送邮件至398879136@qq.com,我们会在3个工作日内处理。非原创标注的文章,观点仅代表作者本人,不代表炎黄立场。

